Unlocking Efficiency: Reducing Redis Memory Utilization with RedisInsight and Optimization Techniques


In the world of modern application development, Redis has become a go-to database choice due to its lightning-fast performance and versatility. However, as your application scales and data volumes increase, efficient memory utilization becomes crucial to maintain optimal performance and cost-effectiveness. In this article, we will explore how RedisInsight, a powerful monitoring and visualization tool, along with various optimization techniques, can help you unlock efficiency by reducing Redis memory utilization.
Understanding the Challenge
Redis, an in-memory data store, excels at delivering high-speed data access. However, this speed comes at a cost: memory usage. As data accumulates, Redis can quickly consume a significant portion of your server's memory, potentially leading to increased operational costs, performance bottlenecks, and even crashes.
RedisInsight
RedisInsight is an advanced monitoring and management tool that empowers developers and administrators to gain deep insights into their Redis deployments. With its intuitive interface, RedisInsight enables you to visualize key metrics, analyze performance patterns, and pinpoint memory-consuming elements within your Redis instances. The main features of redis insight are:
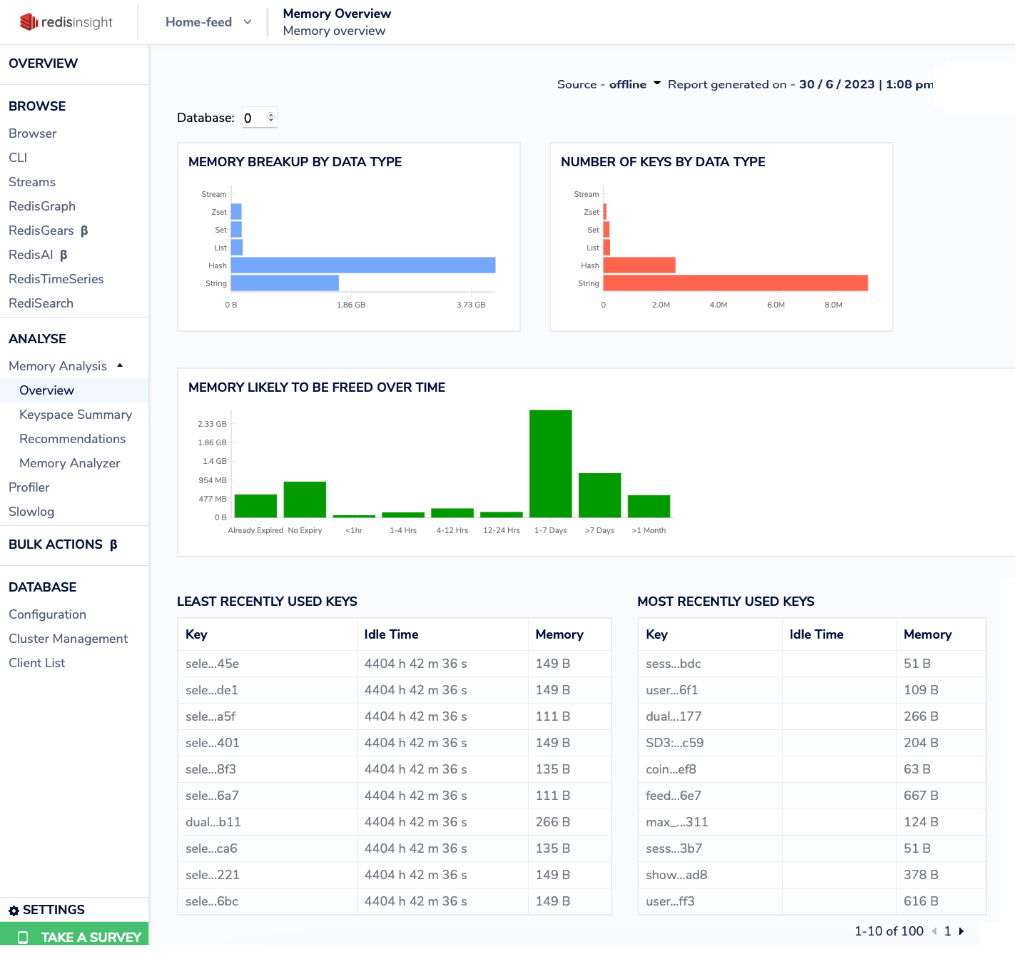
1. Memory Overview:
RedisInsight offers a comprehensive memory overview, showcasing:
Memory Breakup by Data Type: Visualizes memory distribution across various data types, helping you identify the main memory consumers.
Number of Keys by Data Type: Reveals key counts per data type, aiding in understanding memory usage patterns.
Memory Likely to be Freed Over Time: Predicts upcoming memory releases due to key expiration, assisting in resource planning.
LRU and MRU Keys: Displays memory and idle time for least and most recently used keys, aiding in memory optimization
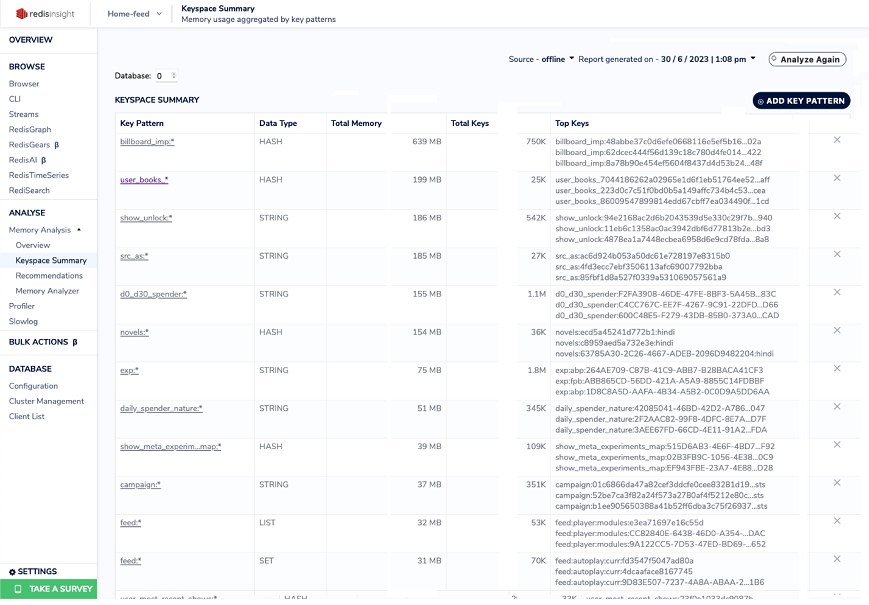
2. Keyspace Summary:
The tool offers a detailed keyspace summary, allowing you to see memory distribution across different data types and keys. This insight helps you identify memory-hungry components within your Redis dataset.
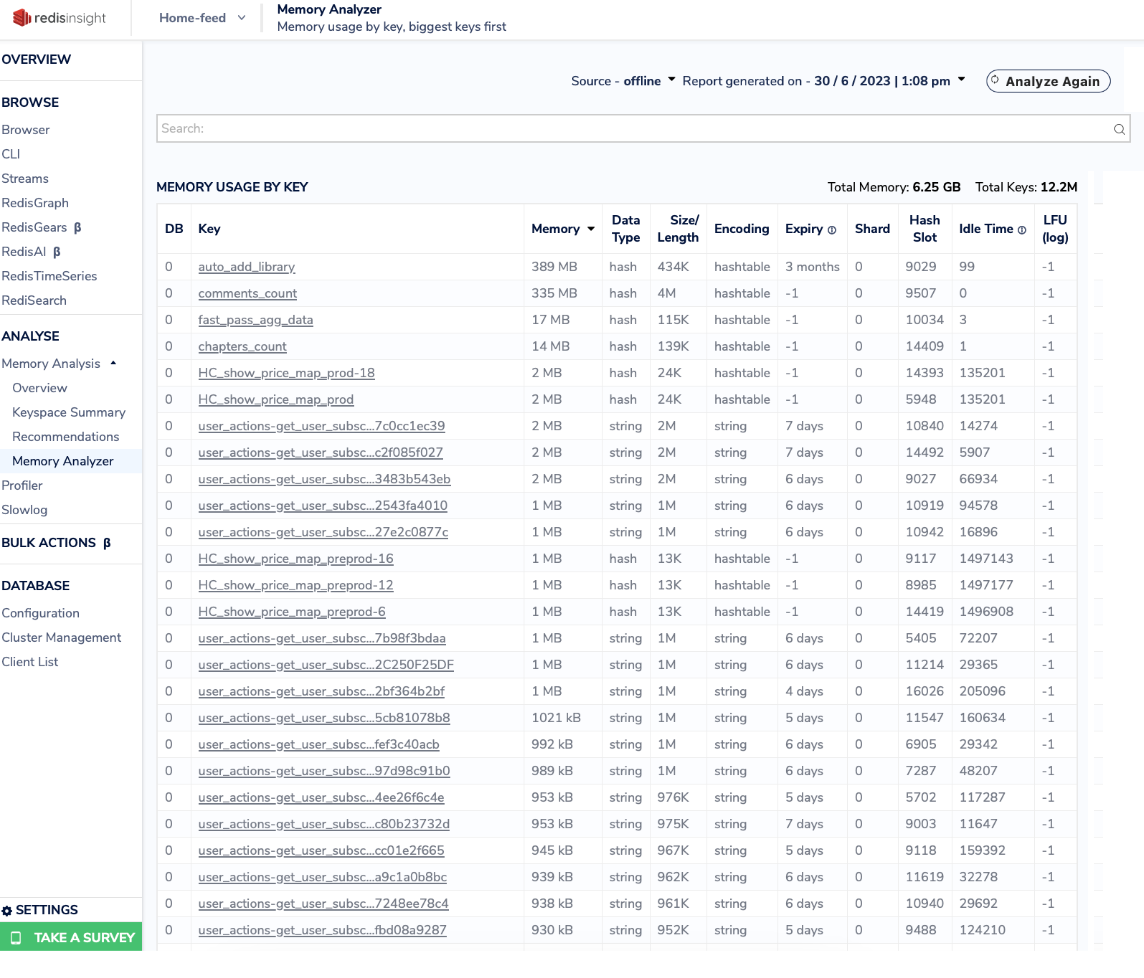
3. Memory Analyzer:
RedisInsight's Memory Analyzer gives you a visual breakdown of memory consumption across various Redis data structures, such as strings, lists, sets, and hashes. This feature enables you to identify memory-intensive data types and focus your optimization efforts.
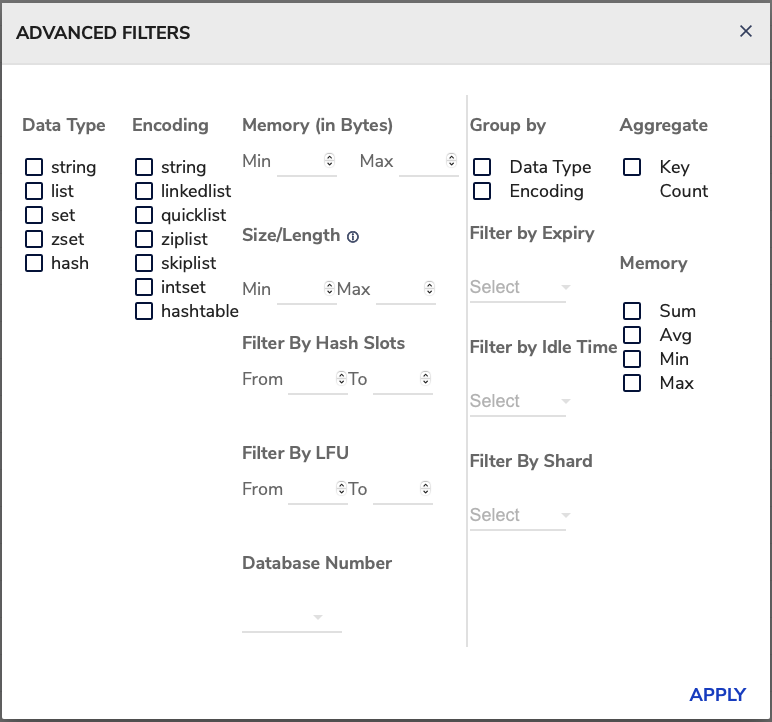
The Advanced Filters can be a powerful tool for identifying and fixing memory problems in your Redis instance. By using the Advanced Filters, you can get a more detailed understanding of how your Redis instance is using memory and you can target your optimization efforts more effectively.
4. Recommendations:
Based on memory usage patterns, RedisInsight provides optimization recommendations. These suggestions are tailored for your specific database.
Optimization Techniques
Armed with insights from RedisInsight, you can implement the following optimization techniques to reduce Redis memory utilization. Below implementation is in Python.
1. Data Expiration:
Expire data automatically by setting a TTL (time-to-live) for keys. This is particularly useful for caching scenarios where data becomes irrelevant after a certain period. Example:
import redis
# Initialize Redis connection
redis_client = redis.Redis(host='localhost', port=6379, db=0)
# Set a key with a value and expiration time
key = "my_key"
value = "my_value"
expiration_time_seconds = 3600
# Use the SET command with the EX option for expiration
redis_client.set(key, value, ex=expiration_time_seconds)2. Data Serialization:
Convert complex data structures, such as objects or JSON, into serialized strings before storing them in Redis. This can significantly reduce memory consumption compared to storing raw objects. Example:
import json
import redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)
data = {"name": "John", "age": 30}
serialized_data = json.dumps(data)
redis_client.set(user_data, serialized_data)For scenarios where specific fields or attributes are frequently queried or analyzed individually, using serialization may not be the optimal choice. It's essential to strike a balance between maintaining the integrity of data and optimizing for efficient access and querying.
When to Use Data Serialization:
Scenario: Storing User Profiles
Suppose you're building a social networking application where user profiles contain various attributes such as name, age, location, and interests. Storing each user's profile as a serialized JSON object can be an efficient way to manage this data.
Example:
import redis
import json
# Initialize Redis connection
redis_client = redis.Redis(host='localhost', port=6379, db=0)
user_id = 12345
user_profile = {
"name": "Alice",
"age": 28,
"location": "New York",
"interests": ["travel", "photography", "hiking"]
}
# Serialize the user profile as JSON
serialized_profile = json.dumps(user_profile)
# Store the serialized profile in Redis
redis_client.set(f"user_profile:{user_id}", serialized_profile)When Not to Use Data Serialization:
Scenario: Real-time Analytics with Time-Series Data
Imagine you're working on a real-time analytics system that tracks user activity in an application. Each user event includes a timestamp and event details. Storing these events as serialized JSON objects might not be the most efficient approach, especially when querying for specific time ranges.
Example:
import redis
import json
# Initialize Redis connection
redis_client = redis.Redis(host='localhost', port=6379, db=0)
user_id = 56789
event = {
"timestamp": 1678921580,
"event_type": "click",
"element_id": "button_123"
}
# Serialize the event as JSON
serialized_event = json.dumps(event)
# Store the serialized event in a sorted set using ZADD
redis_client.zadd(f"user_events:{user_id}", {serialized_event: event["timestamp"]})3. Data Sharding:
Divide your data across multiple Redis instances (shards) to distribute the memory load. This approach is particularly effective when dealing with large datasets that can't fit in a single server's memory.
4. Batch Operations:
Instead of executing multiple commands individually, use batch operations like pipelines to reduce round-trip overhead and improve overall efficiency. Example:
with pipeline() as pipe:
pipe.set("key1", "value1")
pipe.set("key2", "value2")
pipe.execute()5. Key Reduction:
Simplify key naming conventions by eliminating redundant information. Example:
Original Key: "user_preferences_{user_id}"
Optimized Key: "prefs_{user_id}"
Through key reduction, the key was simplified to "prefs_{user_id}," where the preference type information was removed since it was already implied by the context of the data.
6. Hashing:
Incorporate hash values within keys to reduce redundant information. Example:
Original Key: "user_activity_logs_56789_2023-08-09"
Optimized Key: "activity_56789"
In the initial format, the key "user_activity_logs_56789_2023-08-09" represented user activity logs for user 56789 on a specific date (2023-08-09). By incorporating hashing, the date information was hashed and included within the user activity key, leading to the simplified key "activity_56789." This retains the essence of the original key while minimizing redundant information.
Conclusion
Efficient memory utilization is a cornerstone of maintaining optimal Redis performance as your application scales. RedisInsight's powerful monitoring capabilities combined with proactive optimization techniques can help you tackle memory challenges head-on. By understanding your data's behavior and applying intelligent optimization strategies, you can unlock efficiency, reduce operational costs, and ensure your Redis-powered applications run smoothly even as they grow.